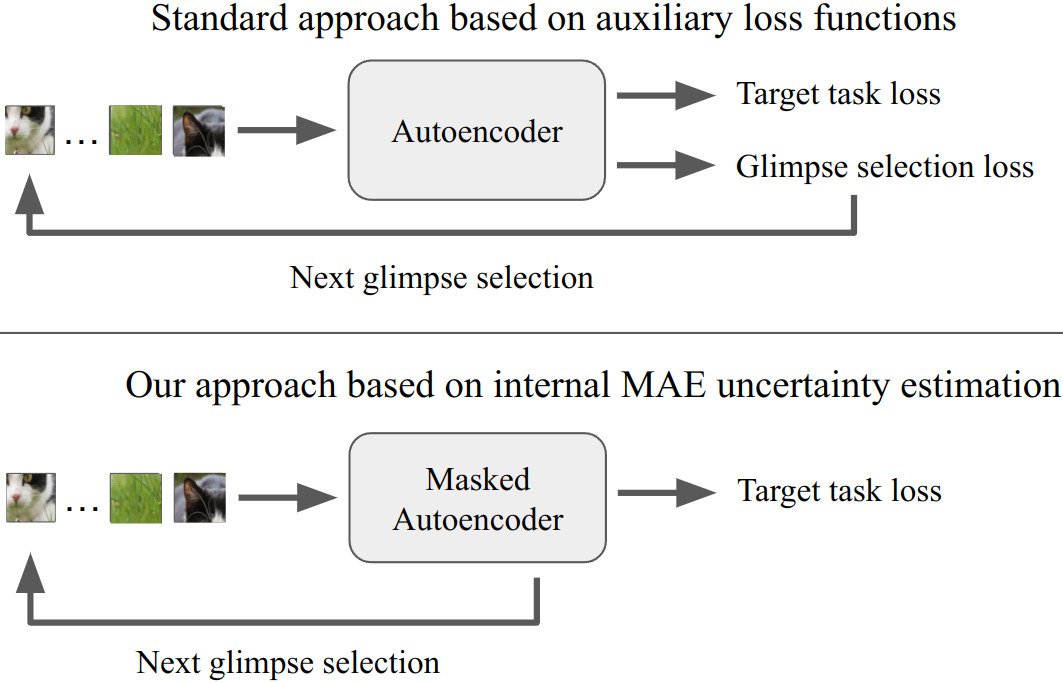
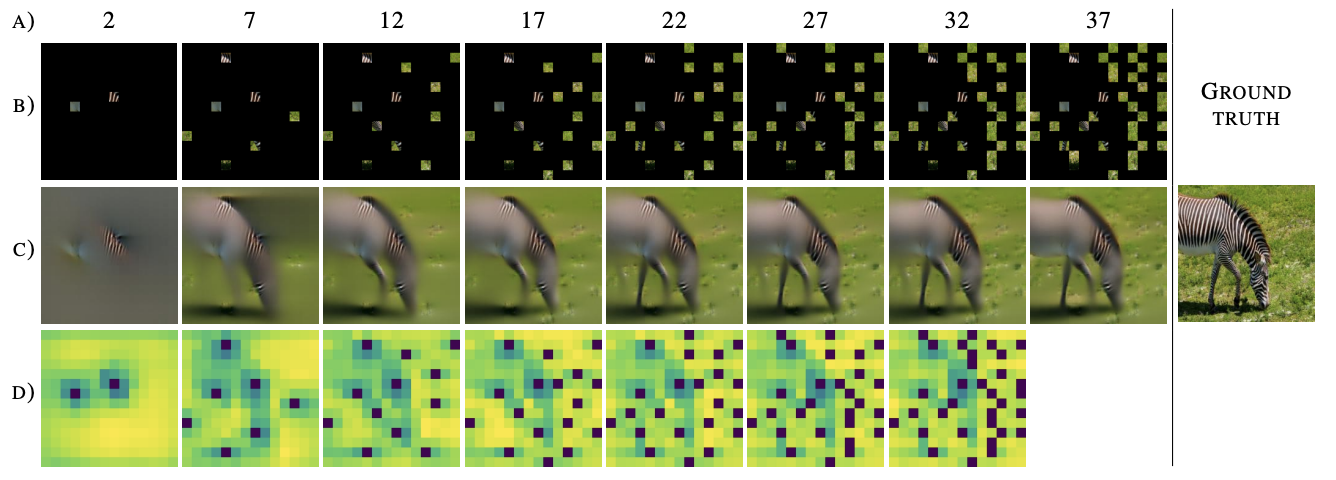
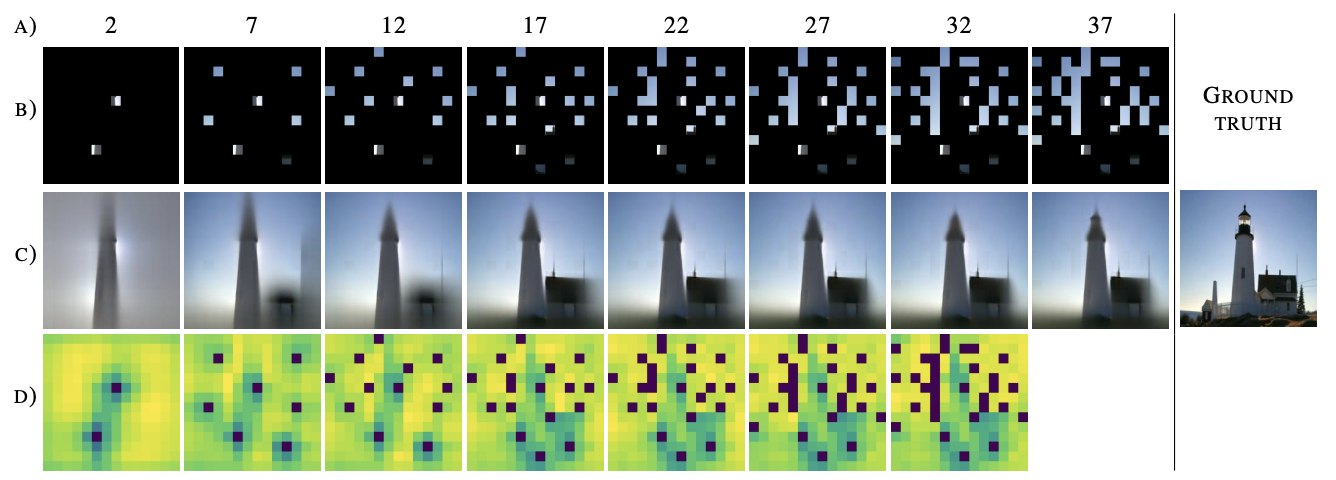
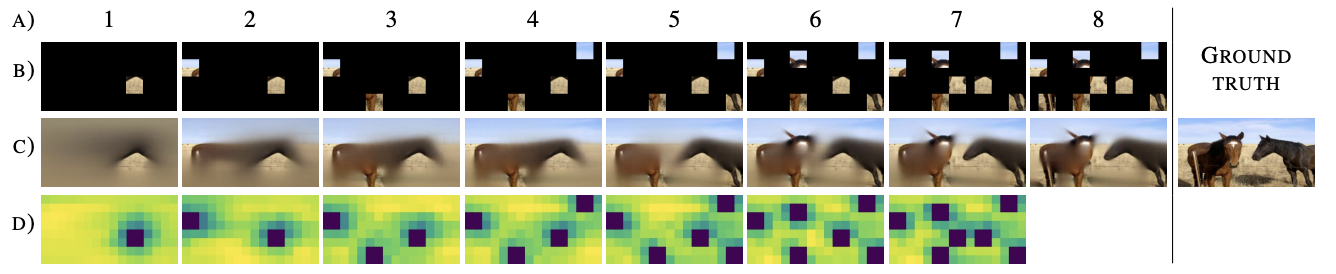
Visual exploration - human versus AI

Humans naturally visually explore surrounding environment, using already observed areas as clues to where the wanted object can be located. At the same time, common state-of-the-art artificial intelligence solutions analyze all available data, which is inefficient and waste time and computational resources. In this project, we introduce a novel Active Visual Exploration method, enabling AI agents to efficiently explore their environment.